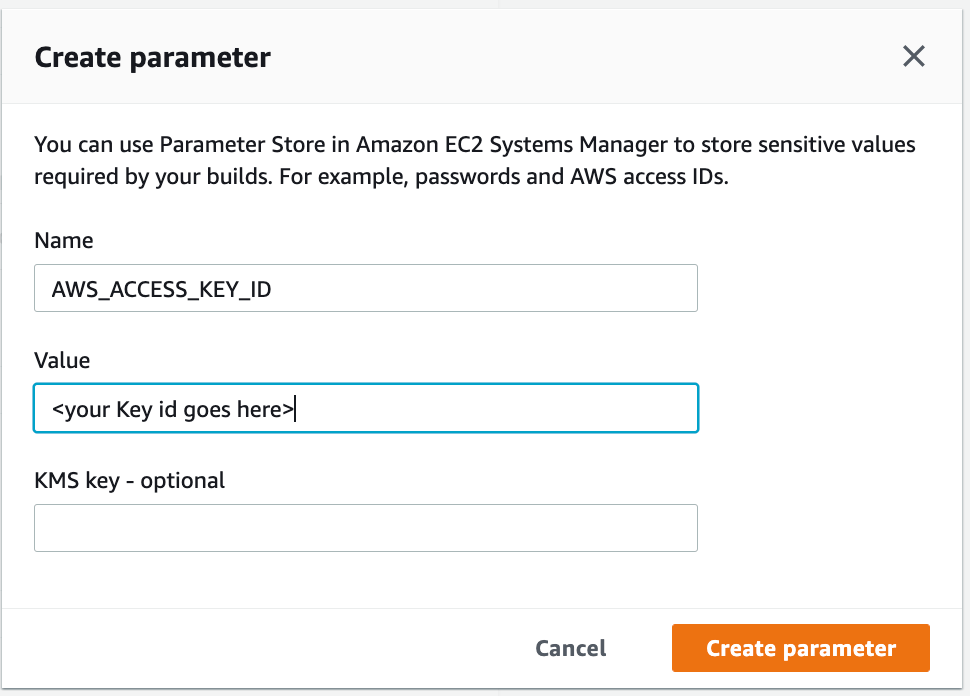
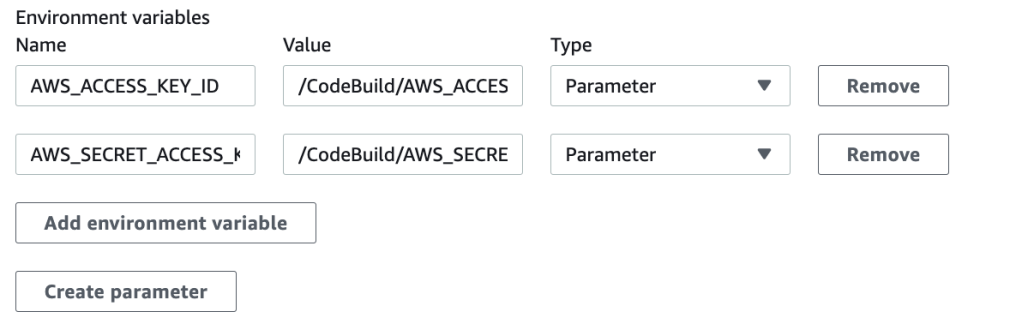
For people not interested in reading the prose, here is the complete source code. The source code contains an AWS lambda function to generate a PDF out of a HTML template.
Introduction
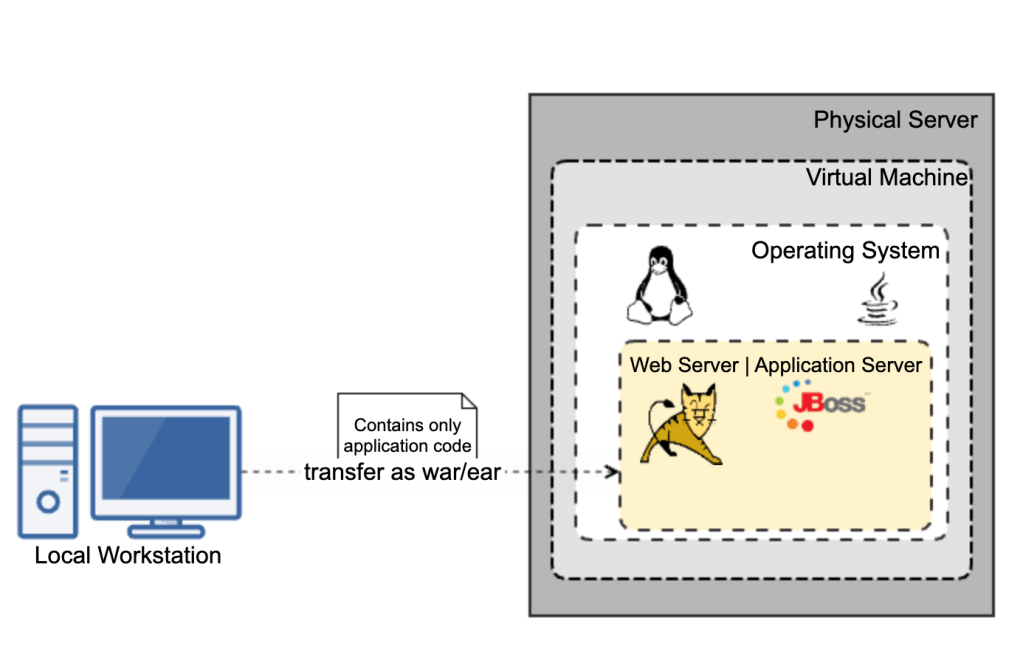
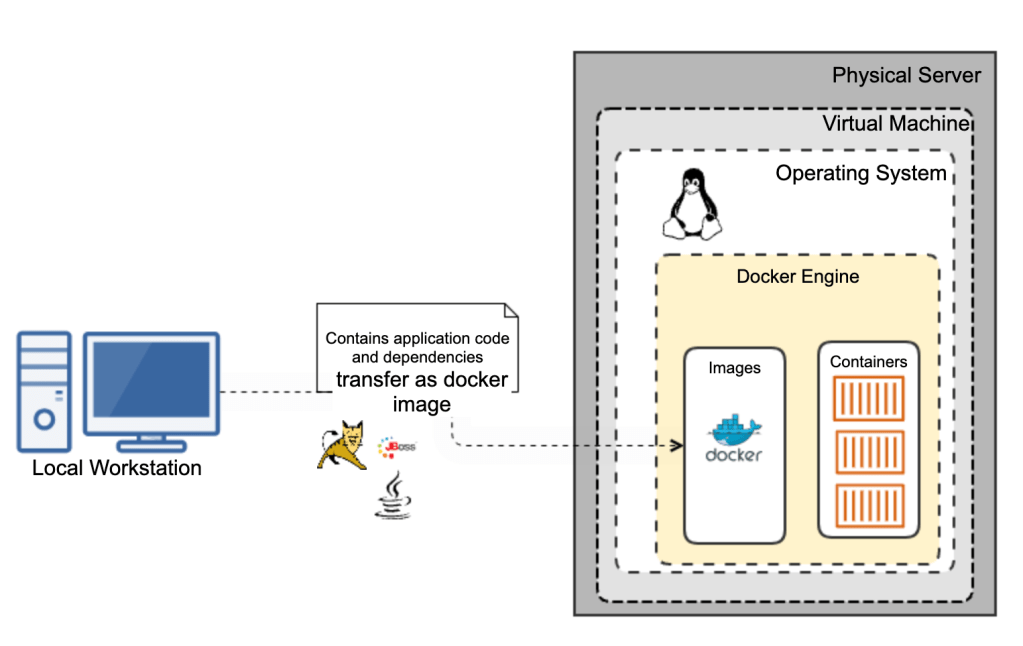
Traditional Java stacks were engineered for applications with long startup times and large memory requirements in a world where the cloud, containers, and Kubernetes did not exist. Java frameworks needed to evolve to meet the needs of this new world.
With AWS lambdas, my experience with Java was not good either. And “cold start” of lambda makes it even worse making it non-ideal for customer facing applications that requires realtime response.
Let’s see how we can overcome this performance bottleneck of Java and create super performant Java lambdas using Quarkus native executables.
What is Quarkus?
Quarkus was created to enable Java developers to create applications for a modern, cloud-native world. Quarkus is a Kubernetes-native Java framework tailored for GraalVM and HotSpot, crafted from best-of-breed Java libraries and standards. The goal is to make Java the leading platform in Kubernetes and serverless environments while offering developers a framework to address a wider range of distributed application architectures.
Say Hello World
Normally everything goes well if you follow the quarkus getting started guide(We need to take extra care only when adding external dependencies). So for a hello world its pretty straight forward. In my case, I started with the AWS Gateway REST API maven archetype
mvn archetype:generate \
-DarchetypeGroupId=io.quarkus \
-DarchetypeArtifactId=quarkus-amazon-lambda-rest-archetype \
-DarchetypeVersion=2.11.2.Final
Maven archetype generates few sample endpoints as well which is good to do a hello world test deploying to AWS. Build the native binary using below command (note that we need a linux compatible binary to run it as AWS lambda). If you are running on Linux machine with GraalVM installed, -Dquarkus.native.container-build=true can be omitted.
quarkus build --native --no-tests -Dquarkus.native.container-build=true
# The --no-tests flag is required only on Windows and macOS.
Quarkus build generates the sam yaml files as well. We can use the generated sam file to test locally as well as to deploy to AWS. To test locally,
sam local start-api --template target/sam.native.yaml
And deploy to AWS lambda using
sam deploy -t target/sam.native.yaml -g
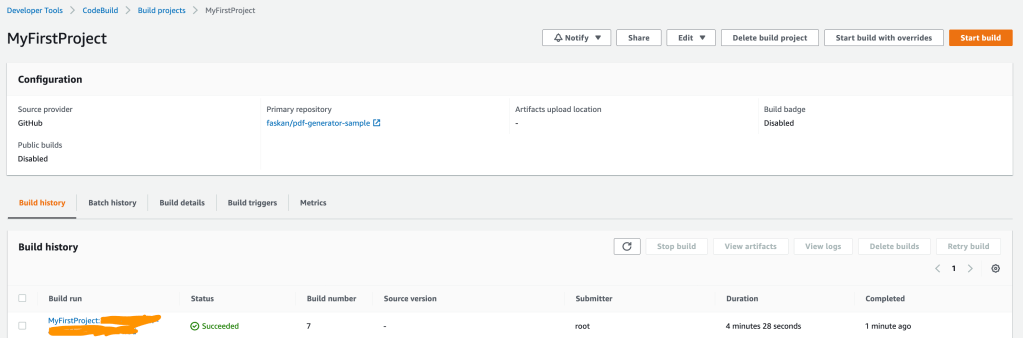
We are done with the hello world now. Hit the API and feel the magical performance. Even though the first hit took 1 or 2 seconds (which was even worse in normal Java lambda), the subsequent hits were all milliseconds.
A better Use-case
Let’s look at a better use case now for a better evaluation. The use-case that I have chosen here is a simple PDF generation restful API. Normally it takes 3-5 seconds on an average for a plain Java lambda to respond (provided with a memory size of 4 Giga bytes). Cold start makes it even 10 seconds or more to respond for such an API.
The API accepts a JSON request, creates a PDF file using the JSON data and uploads the same file to AWS S3. We’ll make use of a templating engine to apply data on a HTML template and convert it to a PDF file.
Let’s start with the dependencies. Note that not all libraries work out of the box with Native binaries. So my first preference was to find compatible quarkus alternative libraries.
For example, in my plain Java lambda, I was using thymeleaf library for HTML templating. But quarkus has qute library as an alternative. Here is the list of libraries that I have used in my project.
- io.quarkus:quarkus-resteasy-qute – for HTML templating
- org.xhtmlrenderer:flying-saucer-pdf – for HTML to pdf conversion. (Does not work out of the box. Needs additional configuration to make it work)
- io.quarkus:quarkus-awt – AWT extension for quarkus
- io.quarkiverse.amazonservices:quarkus-amazon-s3 – Provides S3 SDK apis to add generated pdf file into S3 bucket
- software.amazon.awssdk:url-connection-client – Provides http client for connecting to S3
- io.quarkus:quarkus-rest-client – Rest client to fetch HTML template from remote URL
- io.quarkus:quarkus-rest-client – Rest client to fetch HTML template from remote URL
- io.quarkus:quarkus-rest-client-jackson – Jackson quarkus extension
- org.projectlombok:lombok – Helper library to reduce boiler plate code (https://projectlombok.org/)
Let’s have a look at the code now. To process the HTML template, use qute engine.
@Inject
Engine engine;
public String parseHtmlTemplate(String templateUrl, Object pdfRequest) throws IOException {
String out = new Scanner(new URL(templateUrl).openStream(), "UTF-8").useDelimiter("\\A").next();
Template template = engine.parse(out);
return template.data("invoice", pdfRequest).render();
}
To convert html to pdf
public ByteArrayOutputStream htmlToPdf(String html) throws DocumentException {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
ITextRenderer renderer = new ITextRenderer();
renderer.setDocumentFromString(html);
renderer.layout();
renderer.createPDF(outputStream);
return outputStream;
}
And to save the pdf file to AWS S3
public void saveFile(String fileName, ByteArrayOutputStream outputStream) {
String awsRegion = Optional.ofNullable(System.getenv("AWS_REGION")).orElse("us-east-1");
S3Client s3Client = S3Client.builder()
.region(Region.of(awsRegion))
.httpClientBuilder(UrlConnectionHttpClient.builder())
.build();
s3Client.putObject(PutObjectRequest.builder()
.bucket(System.getenv("PDF_BUCKET_NAME"))
.key(fileName)
.build(), RequestBody.fromBytes(outputStream.toByteArray()));
}
To save file to S3, first we have to create an S3 bucket in AWS. It is possible to automate the same using sam. To do the same, I have copied the generated sam.*.yaml file to the project root folder. And made couple of modifications to make it work.
Create new S3 bucket in Resources
PdfBucket:
Type: AWS::S3::Bucket
Correct code uri – CodeUri: target/function.zip
Modify policies to provide S3 access to lambda
Policies:
- S3FullAccessPolicy:
BucketName: !Ref PdfBucket
- AWSLambdaBasicExecutionRole
Inject bucket name to environment variables. PDF_BUCKET_NAME: !Ref PdfBucket
And name of the S3 bucket created by SAM is injected to Java code as an environment variable.
So far everything was good, I deployed my code to AWS and I was expecting it to work. But unfortunately it wasn’t working. To debug it further, I deployed the JVM stack using sam.jvm.yaml and found that it was working in jvm stack.
From the native stack’s cloud watch logs, I realised that native binary needs additional configuration to work with flying saucer library. This library expects certain resources which were not available in the native binary. Following these tips from quarkus, I made the below changes in application.properties to include all necessary resources in the native binary.
quarkus.native.additional-build-args=--native-image-info,\
-H:ResourceConfigurationFiles=resources-config.json,\
--initialize-at-run-time=sun.lwawt.macosx.CInputMethod\\,\
com.lowagie.text.pdf.PdfPublicKeySecurityHandler
{
"resources": [
{
"pattern": ".*\\.html$"
},
{
"pattern": ".*\\.conf$"
},
{
"pattern": ".*\\.dtd$"
},
{
"pattern": ".*\\.css$"
},
{
"pattern": ".*\\.afm$"
}
]
}
Although the configuration required to make it work was minimal, the debugging process to identify the problem was time consuming.
Challenges:
- Beware of libraries that use reflections, class path resource or runtime loading. Native compilation won’t be able to identify all resources needed for runtime.
- There were instances where in there were no failures in the logs but it simply doesn’t work when we use a non-compatible library.
- You would need exceptional debugging skills if you don’t find clues in the logs.
- Native compilation is a time consuming process and so every trials are time consuming
In any case, always refer quarkus native image tips for better debugging.
Even though debugging the native image was a bit difficult, the resulting performance overweighs all those difficulties. The performance of my API has gone from 3-5 seconds to milliseconds. And from more than 10 seconds of cold start to less than 5 seconds which is more than 50% improvement in response time.
Feel free to add your comments and feedback.
References:
Official documentation – https://quarkus.io/guides/amazon-lambda-http